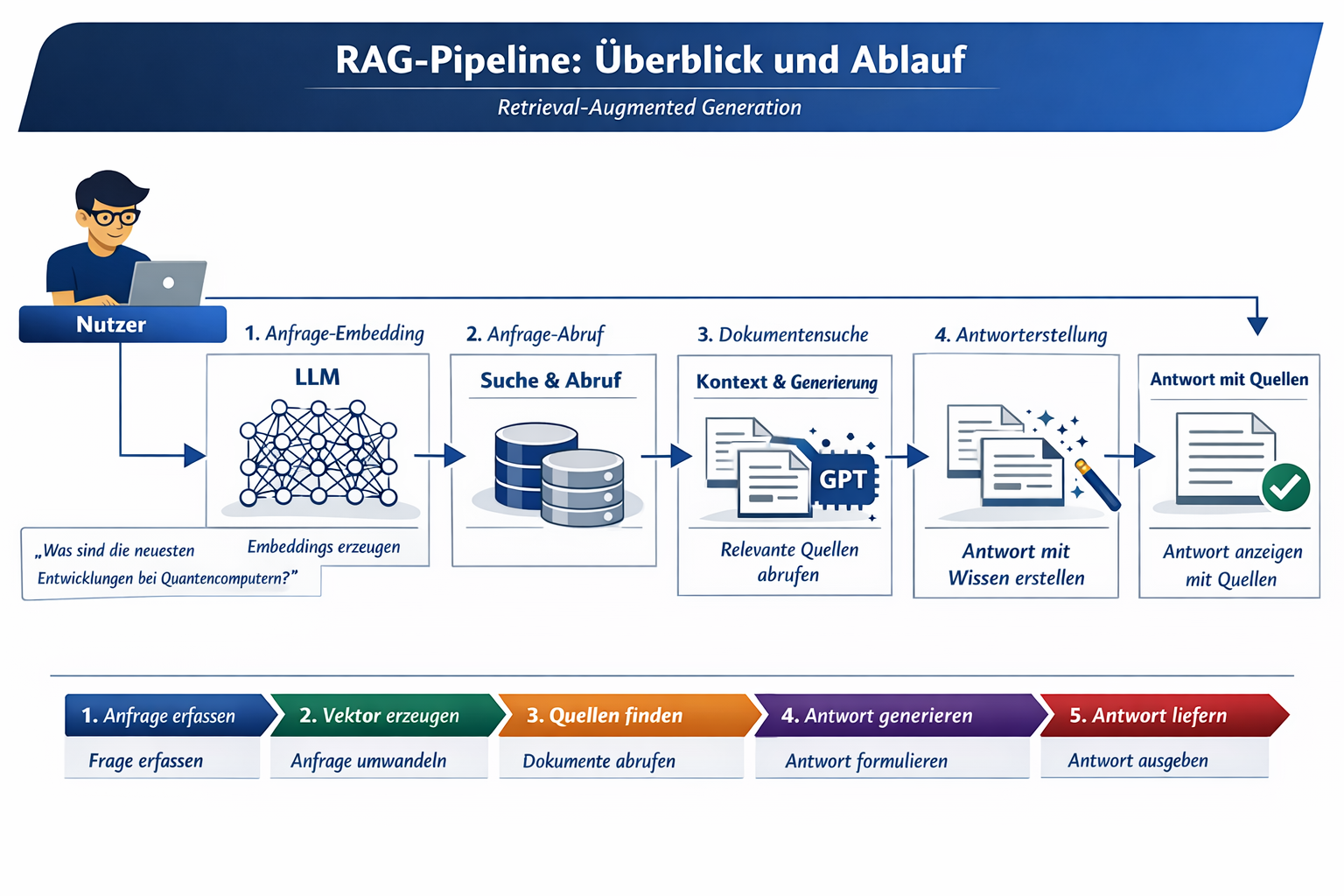
Retrieval‑Augmented Generation (RAG) bezeichnet ein Verfahren, bei dem ein Large Language Model (LLM) während der Antwortgenerierung aktiv auf externe Wissensquellen zugreift. Im Gegensatz zu rein parametrischen Modellen, deren Wissen im Trainingsstand „eingefroren“ ist, kombiniert RAG generative Fähigkeiten mit aktuellen, domänenspezifischen Daten. Das System zerlegt eine Nutzeranfrage zunächst in einen semantischen Vektor und sucht damit in einer Vektordatenbank nach relevanten Dokumenten.
RAG kann aber auch Webseiten (Live‑Web‑Retrieval) oder andere externe Quellen einbeziehen, wenn diese als Teil des Retrieval‑Systems angebunden sind. Diese Dokumente werden anschließend als Kontext an das LLM übergeben, das daraus eine Antwort formuliert. Dadurch sinkt die Wahrscheinlichkeit von Halluzinationen erheblich, weil das Modell nicht „raten“ muss, sondern auf echte Quellen zurückgreift.
RAG ermöglicht zudem Transparenz, da die zugrunde liegenden Dokumente oder Webseiten referenziert werden können. Das Verfahren ist kosteneffizient, weil das LLM selbst nicht neu trainiert werden muss. Gleichzeitig bleibt das System flexibel: Aktualisierungen erfolgen durch das Ersetzen oder Ergänzen der Wissensbasis, nicht durch Modelltraining. RAG gilt daher als Schlüsseltechnologie für KI‑gestützte Unternehmensanwendungen, bei denen Aktualität, Datenschutz und Nachvollziehbarkeit essenziell sind.
Beispiele für Retrieval‑Augmented Generation
Unternehmensinterne Wissensdatenbank
Ein Mitarbeiter fragt: „Wie beantrage ich Sonderurlaub für Weiterbildung?“ Das LLM allein könnte nur allgemeine HR‑Regeln kennen. RAG hingegen ruft die aktuellen internen HR‑Richtlinien aus dem Intranet ab und liefert eine präzise, firmenspezifische Antwort — inklusive Formularlink und Prozessschritten.
Damit werden korrekte, aktuelle, interne Informationen statt generischer KI‑Antworten geliefert.
Technischer Support in der Industrie
Ein Servicetechniker fragt: „Welche Fehlermeldungen können beim Modell XJ‑400 auftreten und wie behebe ich sie?“ RAG durchsucht Wartungshandbücher, Serviceprotokolle und interne Tickets. Das LLM formuliert daraus eine verständliche Schritt‑für‑Schritt‑Anleitung.
Expertenwissen wird in Sekunden verfügbar, ohne dass das Modell auf proprietären Daten trainiert werden muss.
Kundenservice‑Chatbot
Ein Kunde fragt: „Warum wurde meine Bestellung #48392 verzögert?“ RAG ruft interne Logistikdaten ab:
- Versandstatus
- Lagerinformationen
- Lieferantenmeldungen
Das LLM formuliert eine personalisierte Antwort.
Der KI‑gestützte Support antwortet dem Kunden mit echten Informationen statt mit generischen Phrasen.